Low-latency HTTP Live Streaming

Capturing a moment and sharing it with thousands of people worldwide in under a second is undoubtedly cool, but what are the drawbacks? In this blog post, I will provide an overview of the setup, tweaks, and compromises necessary to achieve low latency when streaming over HTTP. Hopefully, this blog post can give you an insight into how low-latency HTTP live streaming pipelines are designed.
How low is low?
Since there aren't any official definitions for the term "low latency," you can stumble across various meanings. In this blog, we discuss "glass-to-glass latency," which means how long it takes between something happening in front of the camera and users seeing it on their screens. We will also label anything under 5 seconds "low latency" and anything under 1 second "ultra-low latency."
For reference, regular live streaming over HTTP latency is usually 20 to 40 seconds, and digital TV broadcasts take around 4 to 6 seconds to reach the audience.
Use cases
There are a few use cases where low latency might be absolutely crucial. For example, streamers on social media need to be able to react promptly to their audience in chat. Keeping the stream engaging is impossible if there's a 30-second latency in the communication channel. The same goes for major sports events. You want to see the goal yourself before you hear your neighbor cheering.
Why HTTP?
HTTP is a request-response protocol that currently underlies all web technologies. It's been around for decades and is, therefore, highly supported and has very mature client and server implementations. This is the main advantage over newer solutions such as WebRTC, which, although initially meant for video calls, is also sometimes utilized for low-latency streaming.
Using HTTP also gets you DVR and VOD by default, meaning you can use the same media files you transcoded for low latency for VOD later. You can also easily fall back to normal latency for clients that don't support low latency without a need to re-encode the media files. This is especially useful for social media platforms, where you have a lot of long-tail broadcasts with 0-10 users, so it's extremely helpful to reuse the files the way they are. In general, if you have a few really popular channels, like traditional broadcasts, re-encoding VOD to achieve better compression ratios and bandwidth is very good practice.
Setup
HTTP live streaming is powered by two main competing protocols.
- HLS (HTTP live streaming) by Apple
- MPEG-DASH, an ISO standard from the MPEG
At their core, they operate on the same principle. They split up the original video into video segments, usually a couple of seconds in duration, and then create an index manifest. The index manifest contains general stream info, but most importantly, it lists various video segments. The client then downloads the index and can choose which video segment to download to continue in a seamless stream. It also supports adaptive bitrate, providing the segments in multiple bitrates and resolutions.
In the case of VOD, the index is static, so the client needs to download it only once. In the case of live streaming, you need to keep downloading the index in a loop so you always have the most recent version.
Sources of latency
Let's take a look at a live-streaming pipeline.
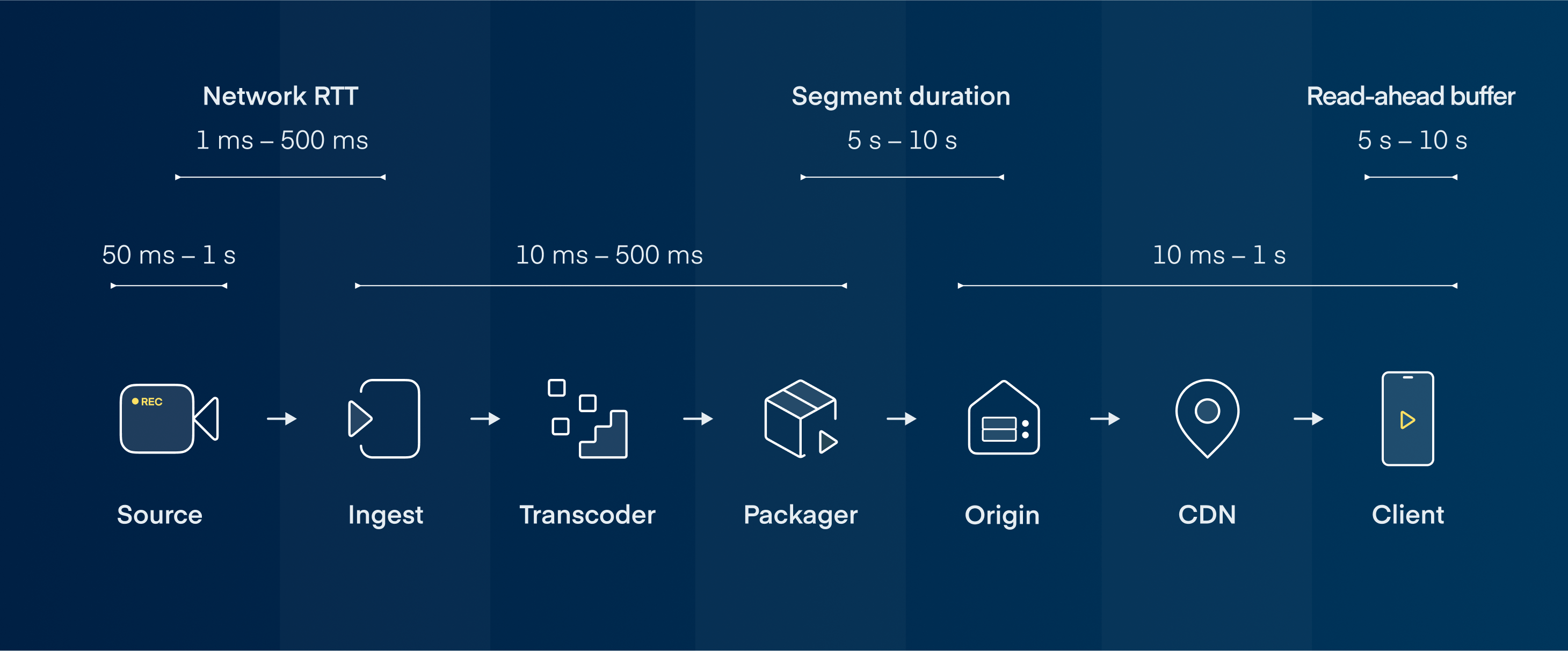
- Source is the device that captures a video.
- Network RTT (Round-Trip Time) refers to the time necessary for the file to be sent and acknowledged by ingest.
- Ingest receives and formats the video so it can be handled by a transcoder.
- Transcoder converts the files to multiple resolutions and bitrates so they're ready for an adaptive bitrate.
- Packager segments the video into small chunks of data and creates the index manifest.
- Origin (storage) is where the files are waiting to be served to the Client.
- CDN serves the data optimally from the origin or from the edges where the content is cached.
- Client is the device the end-user uses to watch the stream, fetch the index manifests, and download the created segments.
- Read-ahead buffer is the pre-load of the video files used to mitigate potential disruptions to the stream.
As the diagram shows, the most significant sources of latency are segment duration, read-ahead buffer, transcoder, and source. I will cover how to optimize these steps in an order that's hopefully most understandable for readers new to this topic. Optimization of the source will be skipped since that's usually determined by the hardware and is out of the scope of this article.
Shortening segment duration
Whenever the packager creates a segment, it uploads it to the origin, and only then can the client fetch it. Once that's done, the whole process repeats itself. If the segments are 5 seconds long, that's another 5-second latency just from this one loop.
The simple solution would be to decrease the duration of the segment, which works but comes with its own problems. You will face two big issues once you start going under two-second segments.
- HTTP overhead – Since you create more requests, you must also process additional data beyond the actual video files.
- Codec inefficiencies – Keyframes take a lot of space and must be present in every segment. If you need them too frequently, less quality is left for other frames, and your compression ratio decreases.
So this can only get you so far.
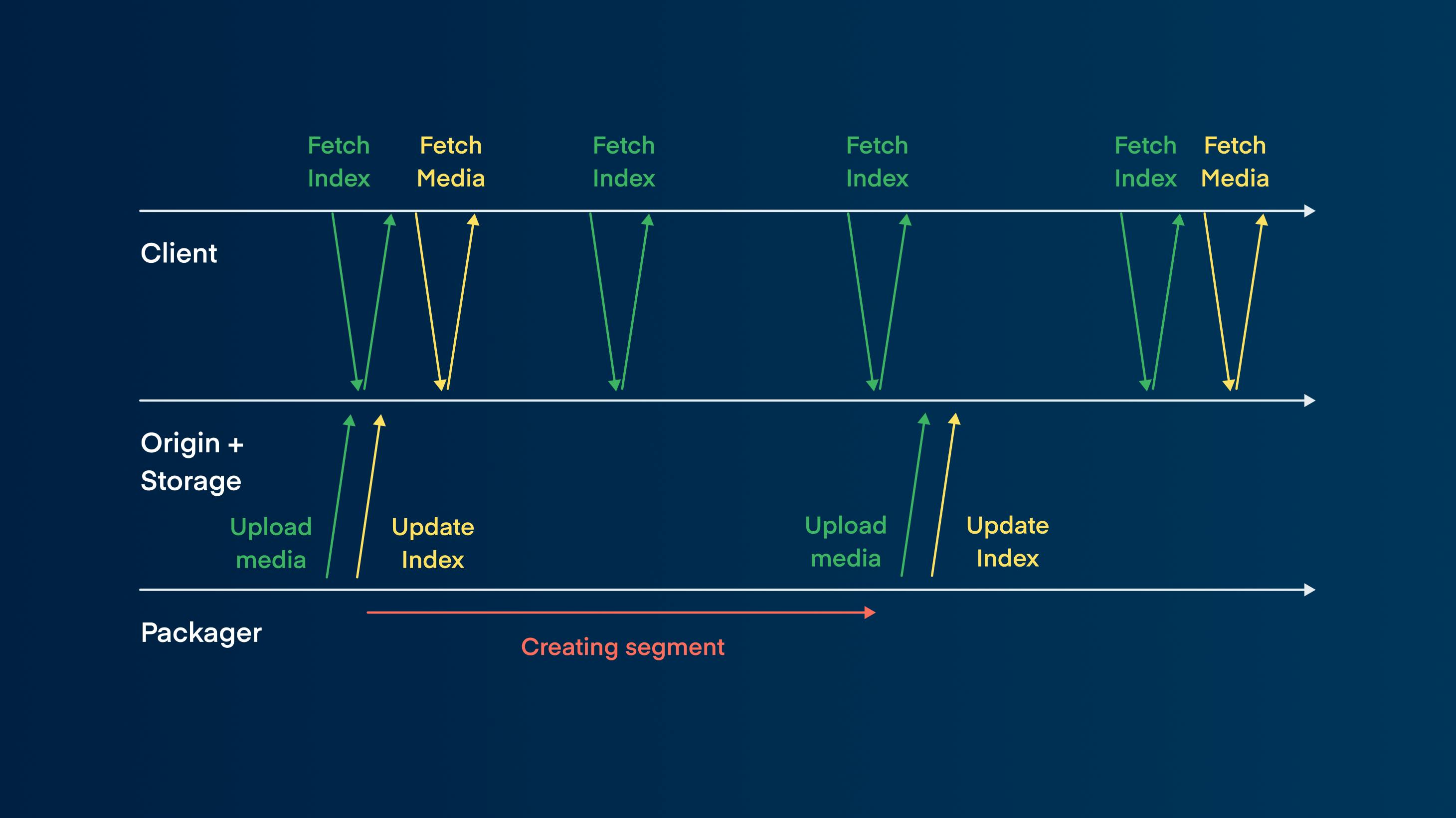
Luckily, MP4 and H.264/H.265 codec don't require the entire segment to be completed before it can be decoded and played. Even better, HTTP supports chunk transfer, which lets you transfer files before they're fully created or their file size is known.
The outcome of this combination is that once the packager starts processing the file, you can simultaneously start uploading it to the origin. At the same moment, the client can also start fetching, decoding, and playing it nearly instantly. Suddenly, we're reducing the delay from 5-10 s to 50-100 ms since it's limited just by network round-trip time.
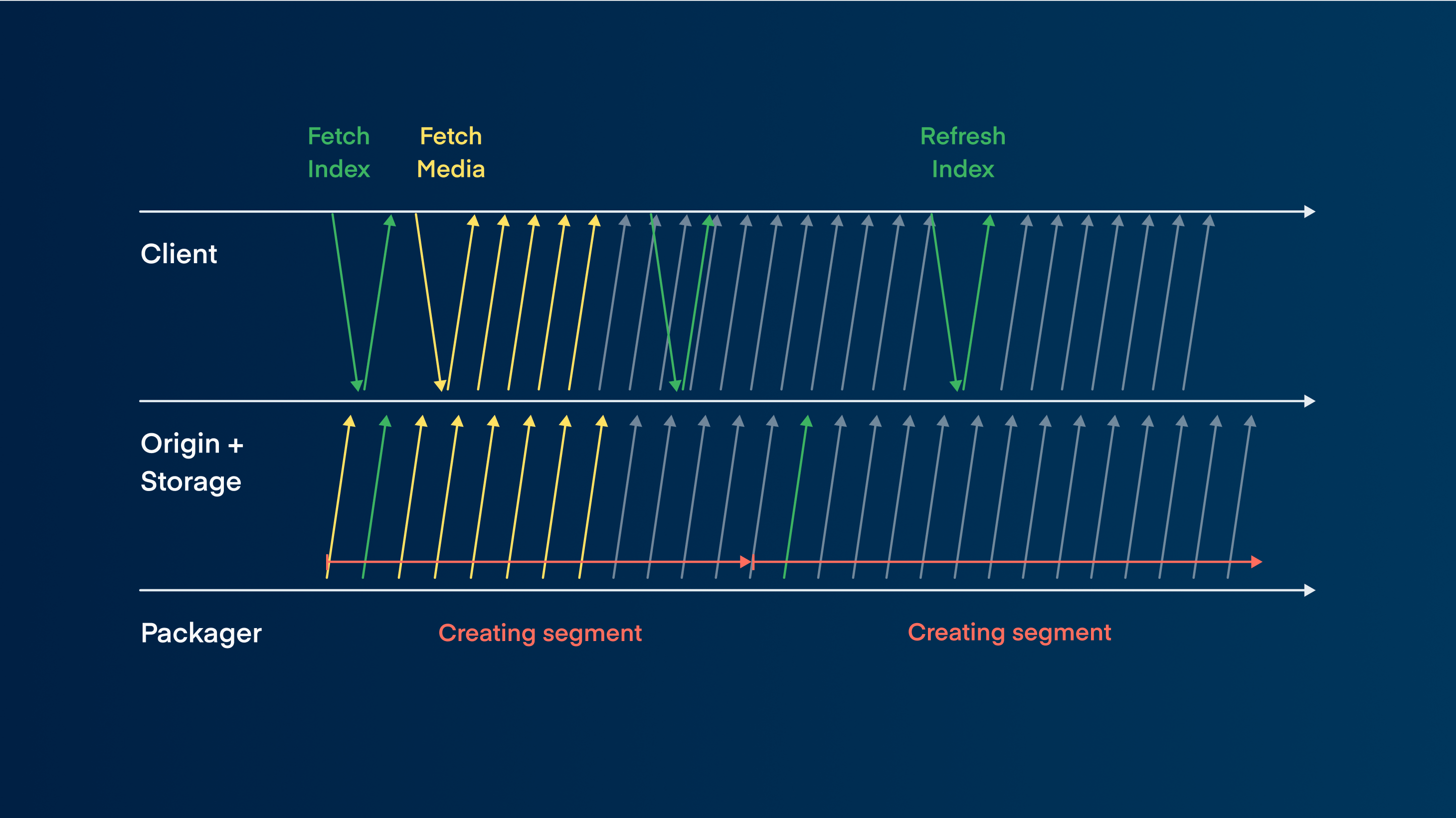
The issue that persists is fetching the index, which still needs to happen continuously.
Index fetching solutions
For MPEG-DASH, we can use Low latency mode, which supports chunk transfer and a segmentation template. The template contains static information about the segments, such as stream start time, segment duration, segment naming, and their path template. This information doesn't need to change every segment. Using this, the client only fetches the index once and then can locally calculate which segment to download to continue the seamless video stream.
<?xml version="1.0" encoding="utf-8"?>
<MPD xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="urn:mpeg:dash:schema:mpd:2011"
xmlns:xlink="http://www.w3.org/1999/xlink"
xsi:schemaLocation="urn:mpeg:DASH:schema:MPD:2011 https://standards.iso.org/ittf/PubliclyAvailableStandards/MPEG-DASH_schema_files/DASH-MPD-edition2.xsd"
profiles="urn:mpeg:dash:profile:isoff-live:2011"
type="static"
mediaPresentationDuration="PT1M30.0S"
maxSegmentDuration="PT4.0S"
minBufferTime="PT10.2S">
<ProgramInformation>
</ProgramInformation>
<ServiceDescription id="0">
<Latency max="6000" min="2000" referenceId="0" target="4000"/>
<PlaybackRate max="1.04" min="0.96"/>
</ServiceDescription>
<Period id="0" start="PT0.0S">
<AdaptationSet id="0" contentType="video" startWithSAP="1" segmentAlignment="true" bitstreamSwitching="true" frameRate="24/1" maxWidth="1920" maxHeight="1080" par="16:9" lang="eng">
<Representation id="0" mimeType="video/mp4" codecs="hev1" bandwidth="8388608" width="1920" height="1080" sar="1:1">
<SegmentTemplate timescale="1000000" duration="4000000" availabilityTimeOffset="3.958" initialization="init-stream$RepresentationID$.m4s" media="chunk-stream$RepresentationID$-$Number%05d$.m4s" startNumber="1">
</SegmentTemplate>
</Representation>
</AdaptationSet>
<AdaptationSet id="1" contentType="audio" startWithSAP="1" segmentAlignment="true" bitstreamSwitching="true" lang="eng">
<Representation id="1" mimeType="audio/mp4" codecs="mp4a.40.2" bandwidth="341000" audioSamplingRate="48000">
<AudioChannelConfiguration schemeIdUri="urn:mpeg:dash:23003:3:audio_channel_configuration:2011" value="6" />
<SegmentTemplate timescale="1000000" duration="4000000" availabilityTimeOffset="3.979" initialization="init-stream$RepresentationID$.m4s" media="chunk-stream$RepresentationID$-$Number%05d$.m4s" startNumber="1">
</SegmentTemplate>
</Representation>
</AdaptationSet>
</Period>
<UTCTiming schemeIdUri="urn:mpeg:dash:utc:http-xsdate:2014" value="https://example.com/time"/>
</MPD>The situation is more complex for HLS. For years, we used community-developed low-latency HLS, which didn't solve the index issue directly but made segments fully HLS and DASH compatible through a common media application format (CMAF). It also supported having the same files as DASH over chunk transfer.
This was until 2018 when Apple made the low-latency HLS incompatible with this community solution and presented its own low-latency HLS. It wasn't very welcomed by the community. It doesn't rely on chunk transfer to transfer complete segments in one request but tries to use separate partial segments. The standard isn't yet stabilized, and we're currently on draft 16 from November 2024, which expires in May 2025.
Currently, you can use low-latency DASH on everything except iOS browsers. This is a bit annoying since even iPadOS is supported, so it really affects only iPhones.
These are your options for reducing the latency of index fetching. If you set it up correctly, you no longer wait 5 to 10 seconds for the index; instead, you push it down to something like 10 milliseconds.
Infrastructure compatibility
Another thing to consider is the compatibility of your infrastructure. Essentially, everything after the packager needs support for chunk transfer or partial segment serving. This might be surprising, but it's less common than you might think. Many storages, for example, AWS S3 object storage, don't support uploading before you know the file size (outside of Express One Zones). Since we're uploading the file as it's being created, we cannot know the file size and, therefore, use it this way.
Nginx is at the core of web servers and many CDNs and it also doesn't support caching files that are not yet complete, at least in its native form. So you need to have a custom implementation of it, like we did, to be able to optimize the stream for low latency.
Overall, consider your whole infrastructure before you start implementing any technology so that you know what you're dealing with.
Read-ahead buffer
Read-ahead buffer pre-downloads segments to make the stream resilient to short network disruptions. So, the latency created is entirely intentional and usually very helpful. If you set it to 10 seconds, you have enough time to download the missing segment or switch to a lower bitrate. This can have a huge impact on the continuity and flow of the stream. Since we're making other compromises for low latency, what happens if we get rid of it?
Well, besides the instabilities, you will face another major problem. The buffer is used to detect when to switch bitrates. If the buffer is full, it may switch to a higher bitrate because your network obviously has no issues getting the files in time. But if your buffer is running low, it's a sign that dropping to a lower bitrate is necessary.
Without the buffer, downloading files as they're being created and judging how fast they're downloaded is much harder. Since you're downloading a 10-second file as it's being created, it'll always take at least 10 seconds to download, so you don't know if your network would be able to download a higher bitrate in time.
There is ongoing PhD research (L2A-LL, LoL+) on this topic, so the solution is still being worked on. What's important is that every time you decide to make changes to the read-ahead buffer, you need to adjust the bitrate ladder accordingly.
Catching up
If you removed (or significantly lowered) the buffer and the user encounters a network problem during a live stream, you still have some options to mitigate the problem. If they download the data later, you can simply skip the missing segment and go back to live, but that would seriously hamper the viewer experience. Instead, you can slightly adjust the playback speed by a few percent. For example, a 5% faster video is practically unnoticeable to the viewer, but it helps you to catch up to the live edge. The same goes for slightly slower playback, which can help you create at least a small buffer if your network is unstable.
This can be done on the fly on a per-user basis, meaning that you can leave a tiny buffer for someone at home with stable wired internet and a bigger buffer for someone who is on the go with mobile internet. More can be done on the network side, but that would be a topic for another blog post, so let's just move further.
Transcoding
Optimizing transcoding is quite complex and relatively difficult on its own. Chances are, if you're reading this blog post, you don't want to develop your own transcoder. Luckily, using existing "off-the-shelf" transcoders is sufficiently efficient. They typically have a low latency switch, which turns off features that increase the delay, like the look-ahead buffer or B frames. Overall, getting under 15 ms is relatively easy with currently available transcoders.
Conclusion
With the methods mentioned in this blog post, you can easily achieve under 5-second or even 1-second latency with ordinary HTTP. Just remember that there will always be a tradeoff between stability and latency, but the technology itself is ready and well-tested. The drawbacks we covered are also not an issue with HTTP; they're fundamental to the nature of the service. So consider what is more important for your broadcast.
Thank you for reading this far, and good luck with adjusting your pipeline. If this short blog sparked your interest in the topic, I consider that a win. To get deeper into it, I recommend the paper Toward One-Second Latency and RFCs 8673, 9317. And of course, I'm always happy to chat with you regarding anything LLLS, streaming, or CDN-related. Just hit me up!

Head of Livestream Engineering